使用三方库Apache Tika库判断上传文件类型的示例。
背景
最近上传服务应用频繁的 Full GC 报警,日志也出现了java.lang.OutOfMemoryError: Java heap space异常。因为是给供应商提供的服务,所以文件大小限制设置的比较大,满足相机拍摄的商品主图上传场景,由后端做压缩存储。
为了解决这次报警的问题,首先是增加了JVM 的堆内存大小:-Xms5g -Xmx5g,然后review了上传代码,发现了一些优化点。
主要是针对上传内容的检测逻辑,为了检测上传的内容是图片类型,代码中使用了多种方式结合的方法。
- 首先针对特定类型进行了文件字节头的判断
- 随后把上传内容的字节转成
BufferedImage类型并获取图片宽高
上面的检测逻辑还是比较完备的,但是因为转成BufferedImage对内存会有额外的消耗,其实可以都通过判断文件字节头来识别类型,这样可以有效减少内存的消耗。
考虑到图片类型判断的完整性,每个类型都单独写方法判断文件头字节太浪费时间,是否存在已有的三方库实现呢?答案是有的:Apache Tika库。
简介
Apache Tika 是开源的文件内容分析工具包,主要的职责是检测与解析文件并提取文件内容。这里我使用其文件的检测能力。
示例
下面使用一个简单的例子介绍一下如何实现其图片类型检查的功能。
首先引入maven依赖
1 | <dependency> |
注意tika-core依赖了commons-io包,这里可能会造成jar包冲突,tika-core中使用了commons-io新版本的类。
(我commons-io是直接依赖的2.5版本,但是tika-core是依赖的2.14.0版本,运行时会有java.lang.NoClassDefFoundError,直接依赖升级到2.14.0版本即可)
1 |
|
输出
1 | image/jpeg |
其实参见Tika 源码就会发现其实Tika对图片的识别也是判断的文件头。
源码
tika 的 detector 有很多实现类: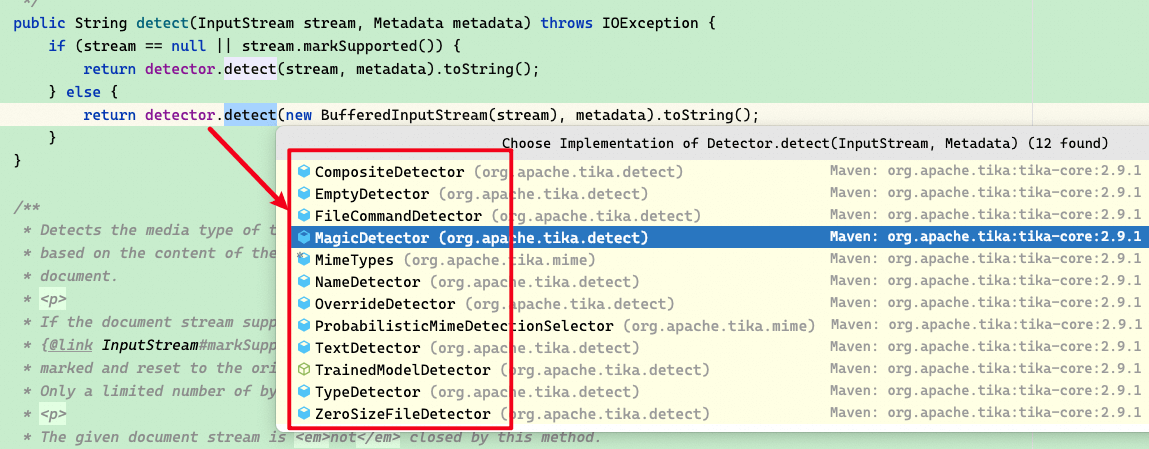
我们看MagicDetector这个实现类(标识文件类型的头几个字节码俗称magic bytes,中文一般叫做魔数头,会破解脱壳的朋友应该不会陌生)。
jpeg格式对应的magic类: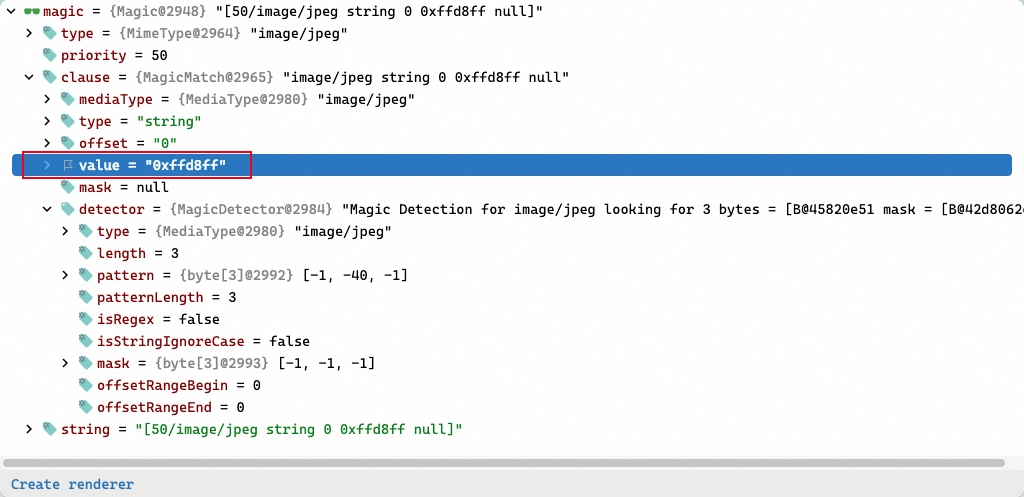
其中已经包含了jpeg文件的识别3个字节码:0xffd8ff, 同时注意下面的detector 的 pattern [-1, -40, -1] 正是 0xffd8ff 的有符号十进制表示。
随后读取了文件的前三个字节: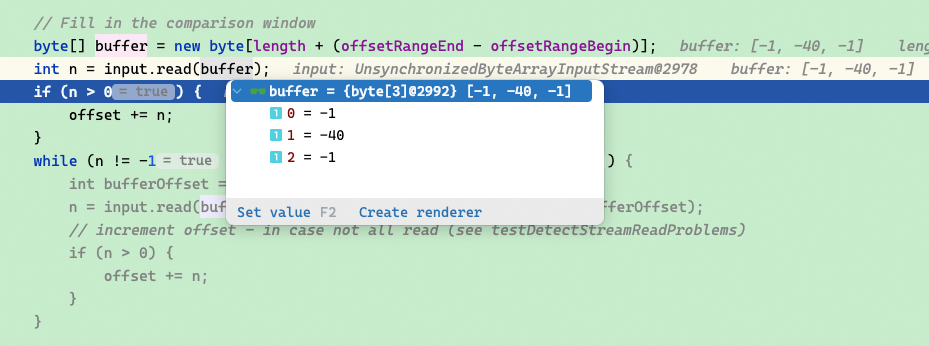
随后代码中做了对比判断是否命中:
1 | boolean match = true; |