最近需要递归查询组织架构人员信息,比较契合 Fork/Join 框架的思想,复习一下。
Overview
Java 7 introduced the fork/join framework. It provides tools to help speed up parallel processing by attempting to use all available processor cores. It accomplishes this through a divide and conquer approach.
(核心就是分治的思想,同MapReduce)
In practice, this means that the framework first “forks”, recursively breaking the task into smaller independent subtasks until they are simple enough to run asynchronously.
(递归的拆分成小任务,然后异步执行)
After that, the “join” part begins. The results of all subtasks are recursively joined into a single result. In the case of a task that returns void, the program simply waits until every subtask runs.
(MapReduce 的的reduce部分,上面拆分的任务结果合并,见下图)
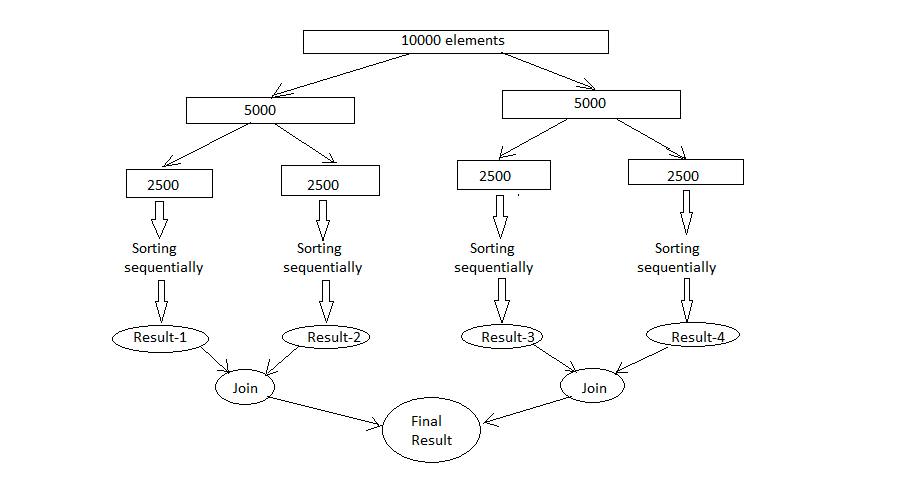
To provide effective parallel execution, the fork/join framework uses a pool of threads called the ForkJoinPool. This pool manages worker threads of type ForkJoinWorkerThread.
(使用ForkJoinPool来提高并行执行的效率)
ForkJoinPool
The ForkJoinPool is the heart of the framework. It is an implementation of the ExecutorService that manages worker threads and provides us with tools to get information about the thread pool state and performance.
(ForkJoinPool是框架的核心,实现了ExecutorService接口)
Worker threads can execute only one task at a time, but the ForkJoinPool doesn’t create a separate thread for every single subtask.
Instead, each thread in the pool has its own double-ended queue (or deque, pronounced “deck”) that stores tasks.
(不是为每个任务都创建一个独立的执行线程,而是固定的工作线程数,每个工作线程都有自己的双端队列,然后使用下面的任务窃取算法来平衡每个线程的任务量)
This architecture is vital(必不可少的) for balancing the thread’s workload with the help of the work-stealing algorithm.
Work-Stealing Algorithm
Simply put(简而言之), free threads try to “steal” work from deques of busy threads.
(任务窃取算法简单说就是 没有工作任务的线程从繁忙线程的双端队列中窃取任务执行)
By default, a worker thread gets tasks from the head of its own deque. When it is empty, the thread takes a task from the tail of the deque of another busy thread or from the global entry queue since this is where the biggest pieces of work are likely to be located.
(为什么是双端队列,因为自己线程获取任务是从队头,而窃取任务是从队尾获取任务。分别从两头来取任务减少对任务资源的竞争)
This approach minimizes the possibility that threads will compete for tasks. It also reduces the number of times the thread will have to go looking for work, as it works on the biggest available chunks of work first.
ForkJoinPool Instantiation
In Java 8, the most convenient way to get access to the instance of the ForkJoinPool is to use its static method commonPool(). This will provide a reference to the common pool, which is a default thread pool for every ForkJoinTask.
According to Oracle’s documentation, using the predefined common pool reduces resource consumption(消耗) since this discourages the creation of a separate thread pool per task.
(使用预先定义的commonPool可以减少资源消耗。下面总结说了,一个应用最好只用一个ForkJoinPool)
1 | ForkJoinPool commonPool = ForkJoinPool.commonPool(); |
We can achieve the same behavior in Java 7 by creating a ForkJoinPool and assigning it to a public static field of a utility class:
1 | public static ForkJoinPool forkJoinPool = new ForkJoinPool(2); |
Now we can easily access it:
1 | ForkJoinPool forkJoinPool = PoolUtil.forkJoinPool; |
With ForkJoinPool’s constructors, we can create a custom thread pool with a specific level of parallelism, thread factory and exception handler. Here the pool has a parallelism level of 2. This means that pool will use two processor cores.
(通常来说并行度一般定义成CPU的核数, commonPool是CPU核数-1 int parallelism = Math.max(1, Runtime.getRuntime().availableProcessors() - 1))
ForkJoinTask
ForkJoinTask is the base type for tasks executed inside ForkJoinPool. In practice, one of its two subclasses should be extended: the RecursiveAction for void tasks and the RecursiveTask<V> for tasks that return a value. They both have an abstract method compute() in which the task’s logic is defined.
(ForkJoinTask是ForkJoinPool中执行的任务的抽象类,有两个继承类:RecursiveAction和RecursiveTask,RecursiveAction不关心返回值,RecursiveTask有返回值)
RecursiveAction
In the example below, we use a String called workload to represent the unit of work to be processed. For demonstration purposes, the task is a nonsensical one: It simply uppercases its input and logs it.
To demonstrate the forking behavior of the framework, the example splits the task if workload.length() is larger than a specified threshold using the createSubtask() method.
The String is recursively divided into substrings, creating CustomRecursiveTask instances that are based on these substrings.
As a result, the method returns a List
The list is submitted to the ForkJoinPool using the invokeAll() method:
1 | public class CustomRecursiveAction extends RecursiveAction { |
We can use this pattern to develop our own RecursiveAction classes. To do this, we create an object that represents the total amount of work, chose a suitable threshold, define a method to divide the work and define a method to do the work.
RecursiveTask
For tasks that return a value, the logic here is similar.
The difference is that the result for each subtask is united in a single result:
1 | public class CustomRecursiveTask extends RecursiveTask<Integer> { |
In this example, we use an array stored in the arr field of the CustomRecursiveTask class to represent the work. The createSubtasks() method recursively divides the task into smaller pieces of work until each piece is smaller than the threshold. Then the invokeAll() method submits the subtasks to the common pool and returns a list of Future.
To trigger execution, the join() method is called for each subtask.
(这里描述的有问题,不是join触发任务执行。 join只是等待任务执行完毕获取结果 , fork或invokeAll是把任务放入线程的任务队列等待执行并立即返回 ,任务被工作线程获取到了就会执行,不会等到join才触发执行,比如RecursiveAction没有join也会执行任务)
We’ve accomplished this here using Java 8’s Stream API. We use the sum() method as a representation of combining sub results into the final result.
Submitting Tasks to the ForkJoinPool
We can use a few approaches to submit tasks to the thread pool.
Let’s start with the submit() or execute() method (their use cases are the same):
1 | forkJoinPool.execute(customRecursiveTask); |
The invoke() method forks the task and waits for the result, and doesn’t need any manual joining:
1 | int result = forkJoinPool.invoke(customRecursiveTask); |
(通常直接使用invoke()方法就可以了)
The invokeAll() method is the most convenient way to submit a sequence of ForkJoinTasks to the ForkJoinPool. It takes tasks as parameters (two tasks, var args or a collection), forks and then returns a collection of Future objects in the order in which they were produced.
Alternatively, we can use separate fork() and join() methods. The fork() method submits a task to a pool, but it doesn’t trigger its execution, We must use the (这里错了).join() method for this purpose
In the case of RecursiveAction, the join() returns nothing but null; for RecursiveTask<V>, it returns the result of the task’s execution:
1 | customRecursiveTaskFirst.fork(); |
Here we used the invokeAll() method to submit a sequence of subtasks to the pool. We can do the same job with fork() and join(), though this has consequences for the ordering of the results.
To avoid confusion, it is generally a good idea to use invokeAll() method to submit more than one task to the ForkJoinPool.
(用invokeAll()提交多个任务)
Conclusion
Using the fork/join framework can speed up processing of large tasks, but to achieve this outcome, we should follow some guidelines:
- Use as few thread pools as possible. In most cases, the best decision is to use one thread pool per application or system.(使用尽可能少的线程池)
- Use the default common thread pool if no specific tuning is needed.(使用默认的
commonPool) - Use a reasonable threshold for splitting ForkJoinTask into subtasks.(使用合理的阈值切分子任务)
- Avoid any blocking in ForkJoinTasks.(避免在ForkJoinTask中使用阻塞)