遍历多层级的树,通常都是用递归,但是递归需要新定义一个方法。代码写多了,方法又不能其他地方复用,想着是不是可以不同递归来遍历多层级的树。用 栈 结构即可。
两种实现 只为少些一个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 @Test public void TravelingTree () { String jsonStr = "[{\"code\":\"0\",\"name\":\"0\"},{\"code\":\"1\",\"name\":\"1\",\"children\":[{\"code\":\"10\",\"name\":\"10\",\"children\":[{\"code\":\"100\",\"name\":\"100\"},{\"code\":\"101\",\"name\":\"101\"}]},{\"code\":\"11\",\"name\":\"11\",\"children\":[{\"code\":\"110\",\"name\":\"110\",\"children\":[{\"code\":\"1100\",\"name\":\"1100\"},{\"code\":\"1101\",\"name\":\"1101\"},{\"code\":\"1102\",\"name\":\"1102\"}]},{\"code\":\"111\",\"name\":\"111\"}]},{\"code\":\"12\",\"name\":\"12\"}]}]" ; List<CodeNameModel> testList = JSON.parseArray(jsonStr, CodeNameModel.class); List<String> codeList = travelTree(testList); codeList.sort(Comparator.comparing(Function.identity())); System.out.println("size: " + codeList.size() + ", content:" + JSON.toJSONString(codeList)); List<String> codeList2 = travelTree2(testList); codeList2.sort(Comparator.comparing(Function.identity())); System.out.println("size: " + codeList2.size() + ", content:" + JSON.toJSONString(codeList2)); } private List<String> travelTree (List<CodeNameModel> testList) { if (CollectionUtils.isEmpty(testList)) { return Collections.emptyList(); } List<String> resultList = new ArrayList <>(); for (CodeNameModel codeNameModel : testList) { resultList.add(codeNameModel.getCode()); if (codeNameModel.getChildren() != null ) { resultList.addAll(travelTree(codeNameModel.getChildren())); } } return resultList; } private List<String> travelTree2 (List<CodeNameModel> testList) { List<String> resultList = new ArrayList <>(); Deque<CodeNameModel> stack = new ArrayDeque <>(); testList.forEach(stack::push); while (!stack.isEmpty()) { CodeNameModel pop = stack.pop(); resultList.add(pop.getCode()); if (CollectionUtils.isNotEmpty(pop.getChildren())) { pop.getChildren().forEach(stack::push); } } return resultList; }
ArrayDeque Deque 是双端队列(Double Ended Queue )的意思 ,ArrayDeque是Java集合框架中提供的一种双端队列(deque)实现。ArrayDeque可以在队列的两端高效地插入、删除元素,也可以作为栈来使用。ArrayDeque是线程不安全的,其长度可以自动扩容,并且长度都必须是2的幂次方。Deque接口,Deque接口提供了双向队列需要实现的方法,接口提供了从头部插入、尾部插入,从头部获取、尾部获取以及删除等操作。ArrayDeque从名称来看能看出其内部使用的是数组来进行存储元素。
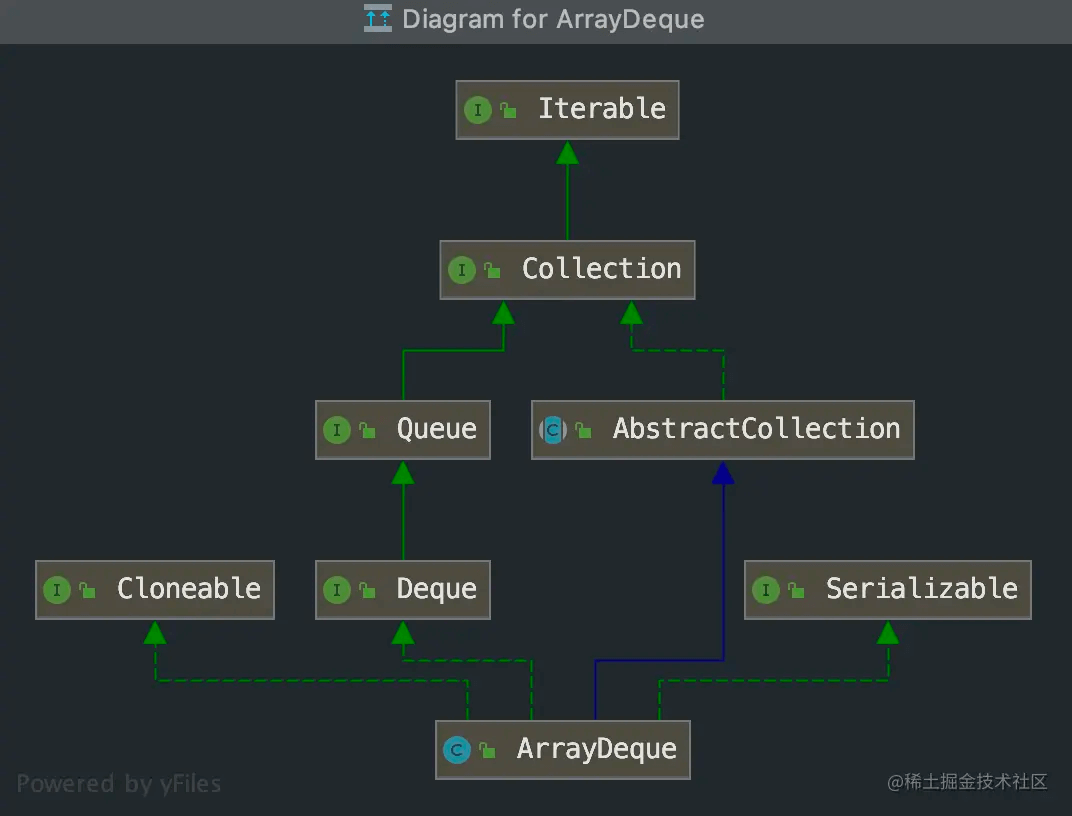
类图
通过类图也可以清晰的看到ArrayDeque继承自Deque接口,并且继承自Queue接口。同时也继承自Collection接口说明可以使用迭代器进行遍历集合。需要注意的是,ArrayDeque不支持null值 。
常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 1.添加元素 addFirst(E e)在数组前面添加元素 addLast(E e)在数组后面添加元素 offerFirst(E e) 在数组前面添加元素,并返回是否添加成功 offerLast(E e) 在数组后天添加元素,并返回是否添加成功 2.删除元素 removeFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将抛出异常 pollFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将返回null removeLast()删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常 pollLast()删除最后一个元素,并返回删除元素的值,如果为null,将返回null removeFirstOccurrence(Object o) 删除第一次出现的指定元素 removeLastOccurrence(Object o) 删除最后一次出现的指定元素 3.获取元素 getFirst() 获取第一个元素,如果没有将抛出异常 getLast() 获取最后一个元素,如果没有将抛出异常 4.队列操作 add(E e) 在队列尾部添加一个元素 offer(E e) 在队列尾部添加一个元素,并返回是否成功 true/fase remove() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将抛出异常(其实底层调用的是removeFirst()) poll() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将返回null(其实调用的是pollFirst()) element() 获取第一个元素,如果没有将抛出异常 peek() 获取第一个元素并不删除,如果返回null 5.栈操作 push(E e) 栈顶添加一个元素 pop(E e) 移除栈顶元素,如果栈顶没有元素将抛出异常 6.其他 size() 获取队列中元素个数 isEmpty() 判断队列是否为空 iterator() 迭代器,从前向后迭代 descendingIterator() 迭代器,从后向前迭代 contain(Object o) 判断队列中是否存在该元素 toArray() 转成数组 clear() 清空队列 clone() 克隆(复制)一个新的队列
源码分析 前文已经介绍过ArrayDeque内部使用的数组元素来进行存储,那数组中是如何控制可以从头部进行插入的呢?难道每次都需要移动所有元素?ArrayDeque实现了一个循环数组来存储元素,并且用 head 和 tail 指针分别指向数据元素的头部与尾部。
不过需要注意的是tail并不是尾部元素的索引,而是尾部元素的下一位,即下一个将要被加入的元素的索引。
1 2 3 4 5 6 7 8 transient Object[] elements; transient int head;transient int tail;private static final int MIN_INITIAL_CAPACITY = 8 ;
ArrayDeque 对数组的大小(即队列的容量)有特殊的要求,必须是 2^n 。我们来看一下allocateElements方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void allocateElements (int numElements) { int initialCapacity=MIN_INITIAL_CAPACITY; if (numElements>=initialCapacity){ initialCapacity=numElements; initialCapacity|=(initialCapacity>>>1 ); initialCapacity|=(initialCapacity>>>2 ); initialCapacity|=(initialCapacity>>>4 ); initialCapacity|=(initialCapacity>>>8 ); initialCapacity|=(initialCapacity>>>16 ); initialCapacity++; if (initialCapacity< 0 ) initialCapacity>>>=1 ; } elements=(E[])new Object [initialCapacity]; }
这里的实现很有意思,对于一个小于2^30的值,经过五次右移和位或操作后,可以得到一个2^k - 1 的值。最后再将这个值+1,得到2^k 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @java public void test(){ Integer val = Integer.valueOf("1000000000", 2); System.out.println(val); System.out.println("org: " + Integer.toBinaryString( val)); System.out.println(">>>1: " + Integer.toBinaryString( val>>>1)); System.out.println(">>>2: " + Integer.toBinaryString( val>>>2)); System.out.println(">>>4: " + Integer.toBinaryString( val>>>4)); System.out.println(">>>8: " + Integer.toBinaryString( val>>>8)); System.out.println(">>>16: " + Integer.toBinaryString( val>>>16)); System.out.println("异或1: " + Integer.toBinaryString( val |= (val>>>1))); System.out.println("异或2: " + Integer.toBinaryString( val |= (val>>>2))); System.out.println("异或4: " + Integer.toBinaryString( val |= (val>>>4))); System.out.println("异或8: " + Integer.toBinaryString( val |= (val>>>8))); } org: 1000000000 >>>1: 100000000 >>>2: 10000000 >>>4: 100000 >>>8: 10 >>>16: 0 异或1: 1100000000 异或2: 1111000000 异或4: 1111111100 异或8: 1111111111
整体思路是每次移动将位数最高的值变成1,从而将二进制所有位数都变成1,变成1之后得到的十进制加上1之后得到值就是2的幂次方的值,这里的操作在JDK1.7版本中的HashMap扩容操作代码是类似的。
那为什么一定要把容量设置成2的幂次方?先看看addFirst方法:
1 2 3 4 5 6 7 public void addFirst (E e) { if (e == null ) throw new NullPointerException (); elements[head = (head - 1 ) & (elements.length - 1 )] = e; if (head == tail) doubleCapacity(); }
注意这一行 elements[head = (head - 1) & (elements.length - 1)] = e; 在队首放入元素到底是放在了(head - 1) & (elements.length - 1) 位置。head位置是0 ,所以head = (head - 1) & (elements.length - 1) = 15,放在了数组的最后一个位置上,如果继续在队首位置添加数据,head = (head - 1) & (elements.length - 1) = 14,可以发现数据一直在数组尾部往前存放数:
这就是为什么需要把空间设置成2的幂次方的原因:快速定位循环数组中的位置来依次往前存放数据 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Test public void testAddFirst () { int head = 0 ; int length = 16 ; head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); head = 2 ; head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); head = (head-1 )&(length-1 ); System.out.println("head = " + head + ", binary = " +Integer.toBinaryString(head)); }
输出
1 2 3 4 5 6 7 head = 15, binary = 1111 head = 14, binary = 1110 head = 13, binary = 1101 head = 1, binary = 1 head = 0, binary = 0 head = 15, binary = 1111
addLast方法同理:
1 2 3 4 5 6 7 public void addLast (E e) { if (e == null ) throw new NullPointerException (); elements[tail] = e; if ( (tail = (tail + 1 ) & (elements.length - 1 )) == head) doubleCapacity(); }